Building a Local RAG Chatbot with Ollama and ChromaDB
Retrieval-Augmented Generation (RAG) is a powerful technique that combines the strengths of large language models (LLMs) with external knowledge sources. In this blog, I'll walk you through how I built a local RAG chatbot using Ollama for LLM inference and ChromaDB as the vector database.
You can find the full backend code on GitHub.
System Architecture
The overall flow of the system is illustrated below:
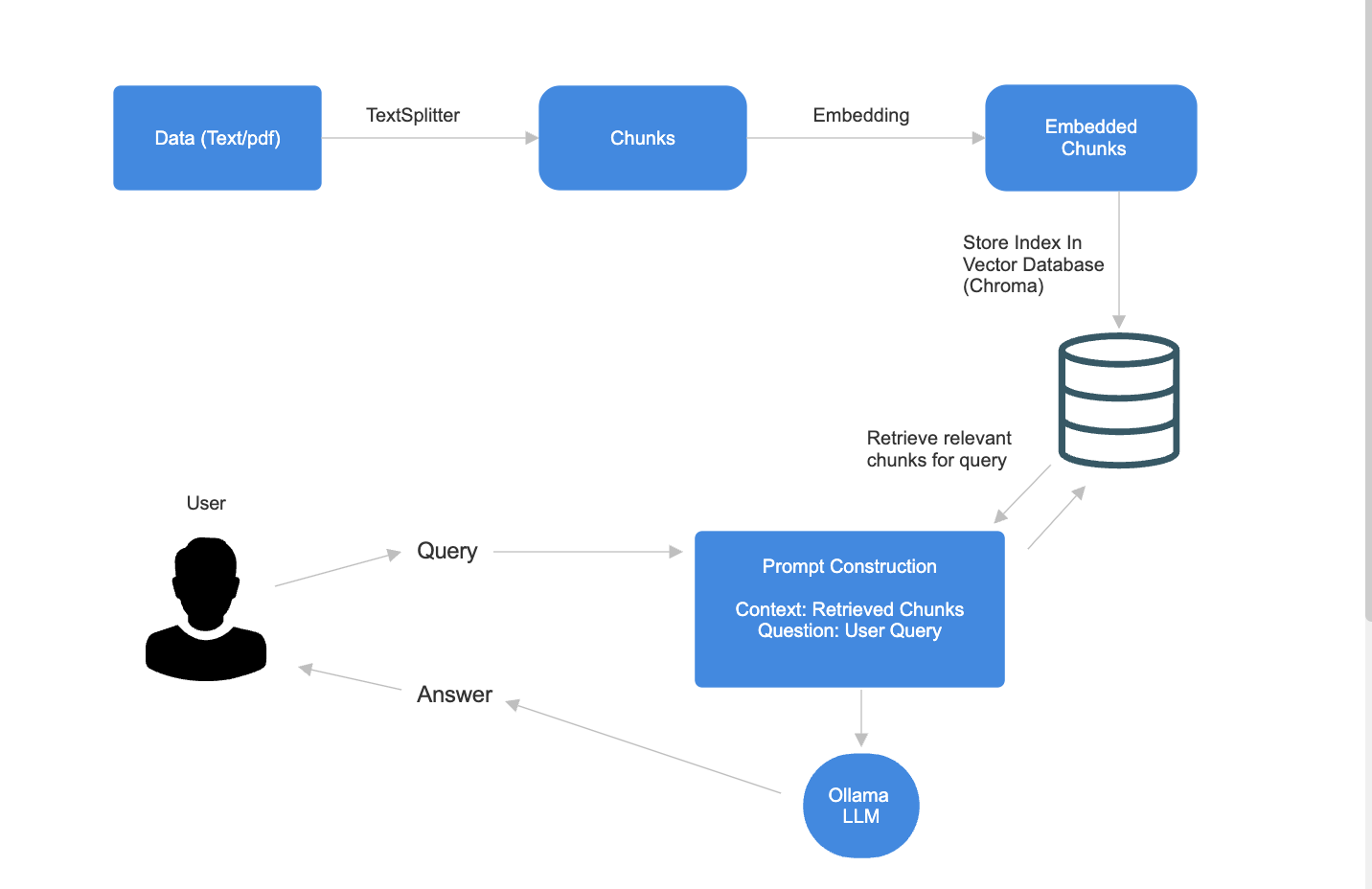
- Data Ingestion: Text or PDF data is split into chunks.
- Embedding: Each chunk is embedded using a sentence transformer.
- Vector Storage: The embeddings are stored in ChromaDB.
- Retrieval: On user query, relevant chunks are retrieved from ChromaDB.
- LLM Augmentation: The retrieved context is sent to Ollama for answer generation.
Key Components
1. Chunking and Embedding
I used the nomic-embed-text model for generating embeddings. Here's a snippet from embed.py:
from sentence_transformers import SentenceTransformer def get_embeddings(texts): model = SentenceTransformer("nomic-ai/nomic-embed-text-v1") return model.encode(texts)
2. Storing Embeddings in ChromaDB
ChromaDB is a lightweight, open-source vector database. Here's how I store the embeddings (see full code):
import chromadb def store_embeddings(chunks, embeddings): client = chromadb.Client() collection = client.create_collection("my_collection") for chunk, embedding in zip(chunks, embeddings): collection.add( documents=[chunk], embeddings=[embedding.tolist()], metadatas=[{"source": "my_data"}] )
3. Querying ChromaDB for Relevant Chunks
When a user asks a question, I embed the query and retrieve the most relevant chunks (see full code):
def retrieve_relevant_chunks(query, collection, model): query_embedding = model.encode([query])[0] results = collection.query( query_embeddings=[query_embedding.tolist()], n_results=3 ) return [doc for doc in results['documents'][0]]
4. Prompt Construction and LLM Inference
The retrieved context is formatted into a prompt and sent to Ollama for answer generation (see full code):
def build_prompt(context, question): return f"Context: {context}\n\nQuestion: {question}\n\nAnswer:" def get_llm_response(prompt): # This function calls the Ollama API running locally import requests response = requests.post("http://localhost:11434/api/generate", json={"prompt": prompt}) return response.json()["response"]
5. Bringing It All Together
The main chat endpoint orchestrates the flow (see full code):
@app.post("/chat") def chat(query: str): relevant_chunks = retrieve_relevant_chunks(query, collection, model) context = " ".join(relevant_chunks) prompt = build_prompt(context, query) answer = get_llm_response(prompt) return {"answer": answer}
Running Locally
- Start Ollama with your preferred model (e.g.,
llama3). - Run the FastAPI backend:
uvicorn main:app --reload - Interact with the chatbot via the
/chatendpoint.
Conclusion
This project demonstrates how you can build a fully local, privacy-preserving RAG chatbot using open-source tools. The combination of ChromaDB and Ollama makes it easy to scale and customize for your own datasets.
Check out the full code on GitHub.
Feel free to reach out if you have questions or want to collaborate!